Join是数据处理领域的的常见场景。许多数据处理系统通过API使得join的使用非常简单。但是,为了能够高效执行,其内部涉及到的算法是非常复杂的。
Flink如何join
Flink使用并行数据库系统中众所周知的技术来有效执行并行join。join必须从其输入数据集中建立联接条件评估为真的所有成对元素。在独立系统中,join的最直接实现是所谓的嵌套循环join(nested-loop-join),该join建立完整的笛卡尔积并评估每对元素的连接条件。这种策略具有O(m*n)复杂性,显然不能扩展到较大的输入。
在分布式系统中,join一般分为两步:
- 两个输入的数据分发到并行实例上;
- 每个并行实例在其整体数据的本地分区上执行标准的独立join算法。
并行实例的数据分布必须确保每个有效连接对都可以由一个实例在本地构建。对于这两个步骤,都可以独立选择多个有效策略,这些策略在不同情况下是有利的。用Flink术语来说,第一阶段称为“传输策略”,第二阶段称为“本地策略”。在下文中,我将介绍Flink的传输和本地战略,以将两个数据集R和S结合在一起。
传输策略
Flink具有两种传输策略,可为join建立有效的数据分区:
- 分区-分区策略(RR)
- 广播转发策略(BF)
Repartition-Repartition策略使用相同的分区功能在其连接键属性上对输入R和S进行了分区。每个分区都恰好分配给一个并行连接实例,并且该分区的所有数据都发送到其关联实例。这样可确保将共享相同联接键的所有元素都运送到同一并行实例,并且可以在本地join。 RR策略的成本是网络上两个数据集的完全改组。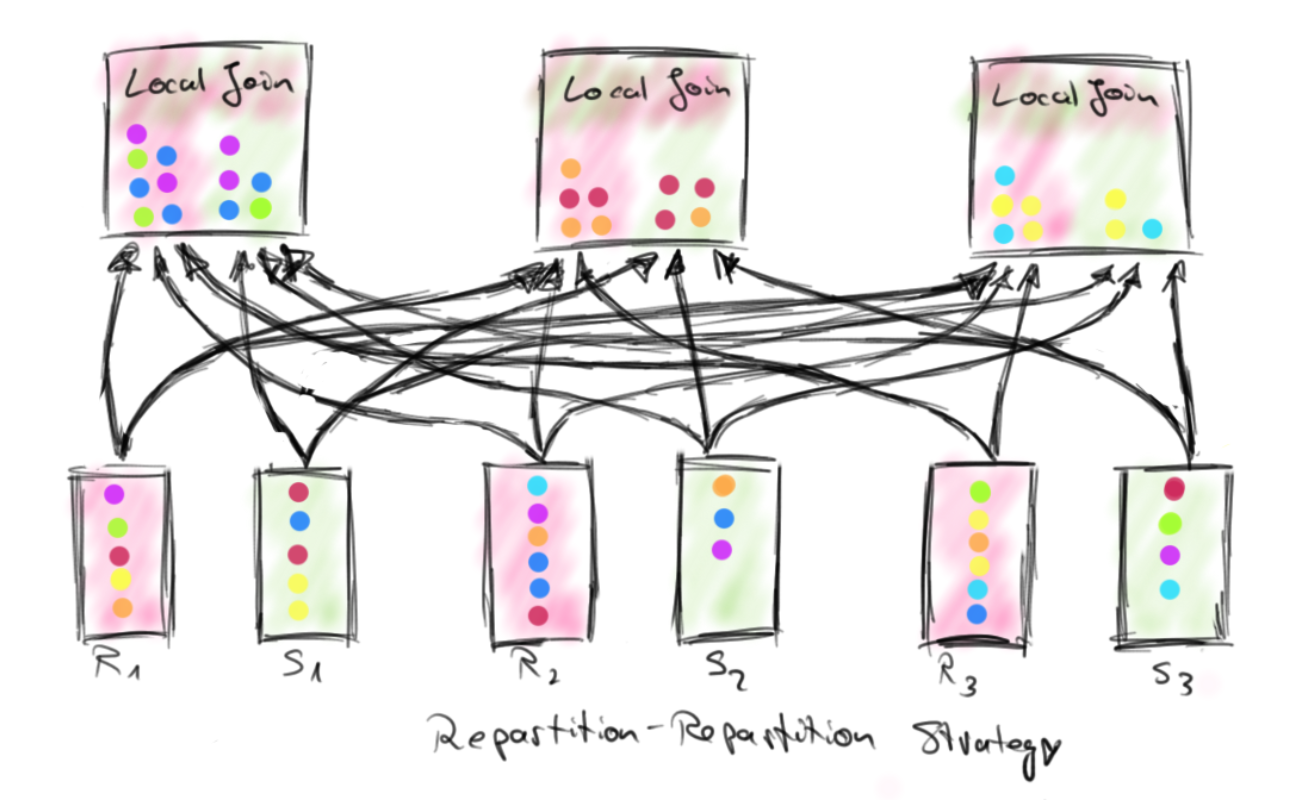
广播转发策略将一个完整的数据集(R)发送到每个拥有另一个数据集(S)分区的并行实例,即,每个并行实例都接收完整的数据集R。数据集S保持本地状态,而不传输了。 BF策略的成本取决于R的大小以及它运送到的并行实例的数量。 S的大小无关紧要,因为S不移动。下图说明了两种运送策略如何工作。
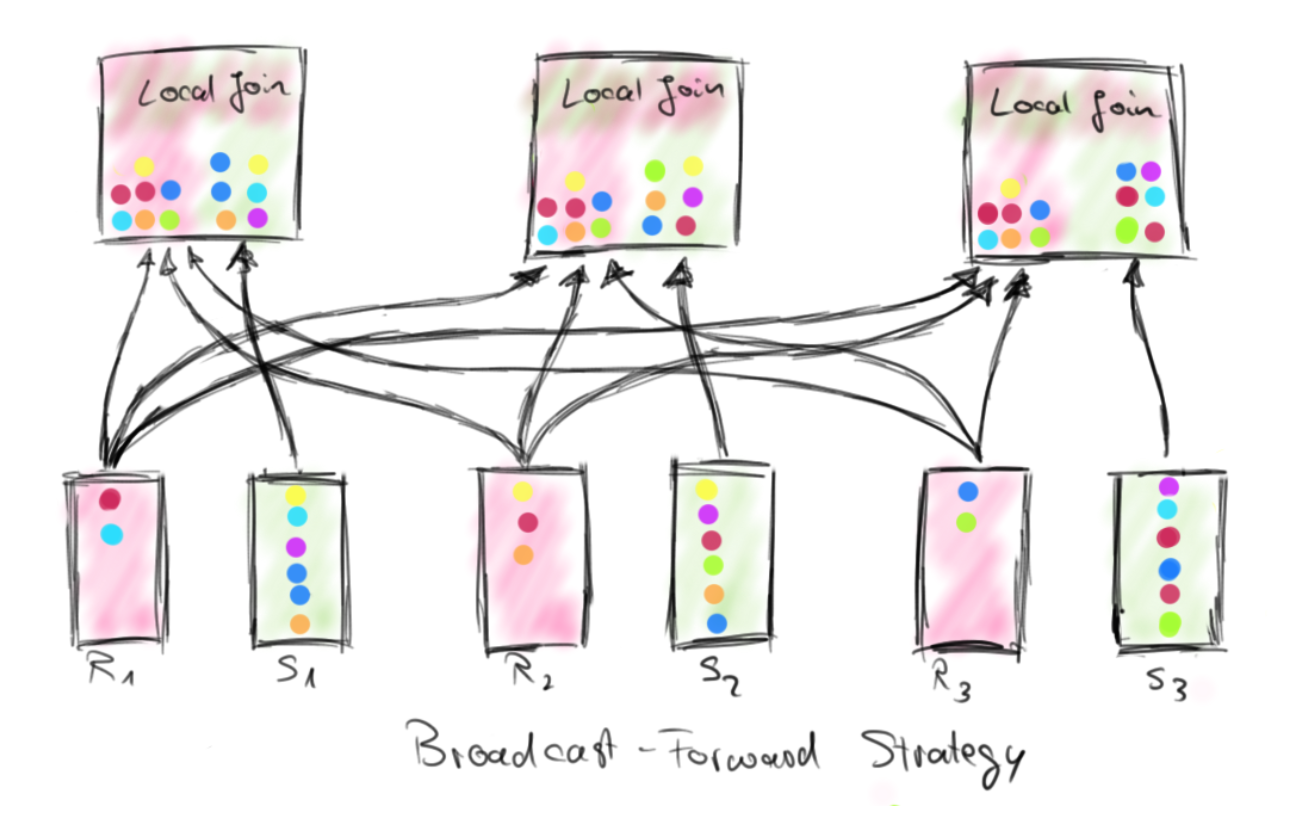
Repartition-Repartition和Broadcast-Forward传输策略根据数据分布以执行分布式join。根据join之前的算子,join的一个或两个输入已经以合适的方式分布在并行实例之间。在这种情况下,Flink将复用这种数据分布,并且仅提供一个输入或完全不提供任何输入。
Flink的内存管理
数据处理算法,比如joining,grouping和sorting最好是在内存中进行,但是,当内存不够时,则需要优雅的把数据写到磁盘中。如何准确识别内存不够,对于Flink(基于JVM的系统)来说有点难。如果识别出错,就会引起OOM。
Flink通过主动管理内存来避免这个问题。当TaskManager启动时,它会分配JVM堆内存的固定部分(默认为70%),该部分在初始化后可作为32KB字节数组使用。这些字节数组作为工作内存分配给所有需要在内存中保存大量数据的算法。该算法将其输入数据作为Java数据对象接收,并将其序列化到其工作内存中。
此设计具有几个不错的属性。首先,JVM堆上的数据对象数量要少得多,从而减少了垃圾回收压力。其次,堆上的对象具有一定的空间开销,并且二进制表示形式更紧凑。特别是许多小元素的数据集将从中受益。第三,算法可以准确知道何时输入数据超出其工作内存,并可以通过将其些已填充字节数组写入实例的本地文件系统中。将字节数组的内容写入磁盘后,可以重复使用它来处理更多数据。将数据读回内存就像从本地文件系统读取二进制数据一样简单。下图说明了Flink的内存管理。
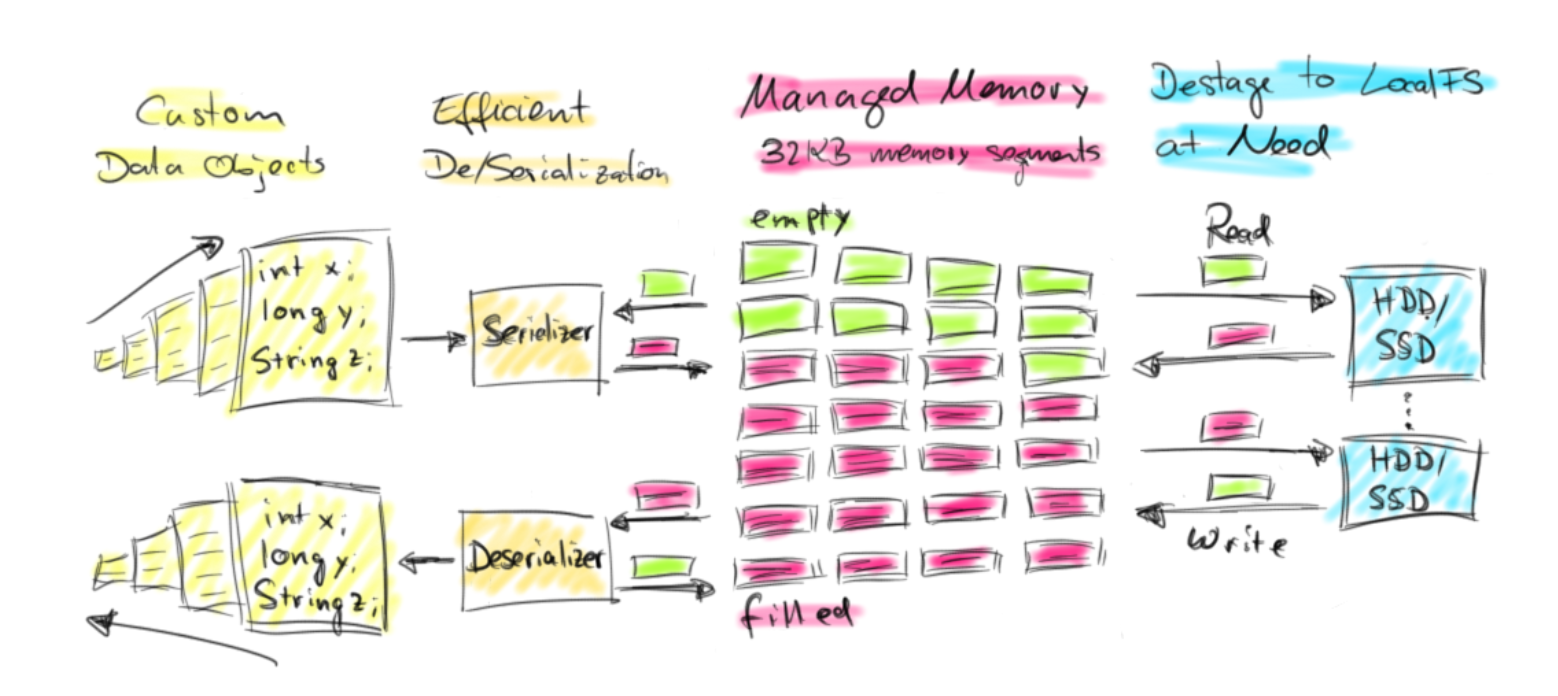
这种主动的内存管理使Flink在有限的内存资源上处理非常大的数据集时非常有效,同时如果数据足够小以适合内存使用,则保留了内存处理的所有优势。与仅将所有数据元素保存在JVM堆中相比,将数据反序列化到内存中或从内存中反序列化具有一定的开销。但是,Flink具有高效的自定义反序列化器,该反序列化器还允许直接对序列化数据执行某些操作(例如比较),而无需从内存反序列化数据对象。
本地策略
在使用Repartition-Repartition或Broadcast-Forward传输策略将数据分布在所有并行join实例上之后,每个实例都运行本地join算法以联接其本地分区的元素。 Flink的运行时具有两种常见的join策略:
- Sort-Merge-Join strategy (SM)
- Hybrid-Hash-Join strategy (HH)
Sort-Merge-Join的工作方式是首先对两个输入数据集的连接键属性进行排序(排序阶段),然后将排序后的数据集合并(合并阶段)。如果数据集的本地分区足够小,则在内存中进行排序。否则,将执行以下操作来进行外部合并排序:收集数据,直到工作内存已满,然后对其进行排序,将排序后的数据写入本地文件系统,接着传入更多的数据到内存来重新开始。在接收到所有输入数据,对其进行排序并写到到本地文件系统之后,就可以获得完全排序的流。这是通过从本地文件系统中读取部分排序的运行并即时对记录进行排序合并来完成的。一旦两个输入的排序流都完成,就可以通过锯齿形顺序读取和合并两个流。下图显示了sort-merge策略的工作方式。
Hybrid-Hash-Join将其输入分为构建端和探针端,并分为两个阶段,即构建阶段和探针阶段。在构建阶段,算法读取构建侧输入,并将所有数据元素插入到内存中的哈希表中,该哈希表由其join键属性索引。如果哈希表超出内存,则哈希表的部分内容(哈希索引的范围)将被写入本地文件系统。在构建侧输入完成之后,构建阶段结束。在探测阶段,算法读取探测端输入,并使用其连接键为每个元素探测哈希表。如果该元素落入散列到磁盘的哈希索引范围内,则该元素也会写入磁盘。否则,该元素将立即与哈希表中的所有匹配元素结合在一起。如果哈希表没有超出内存,则在探针侧输入完成之后完成连接。否则,使用新的哈希表来构建构建端输入的溢出部分。该哈希表由溢出的探测端输入的相应部分探测。最终,所有数据都被合并。如果哈希表没有内存,则Hybrid-Hash-Joins的性能最佳,因为这时任意大的探针侧输入都可以在不落地的情况下即时进行处理。但是,即使构建侧输入超出内存,Hybrid-Hash-Join性能也还可以。在这种情况下,将部分保留内存中的处理,并且仅一部分构建侧和探针侧数据需要写入本地文件系统或从本地文件系统读取。下图说明了Hybrid-Hash-Join的工作方式。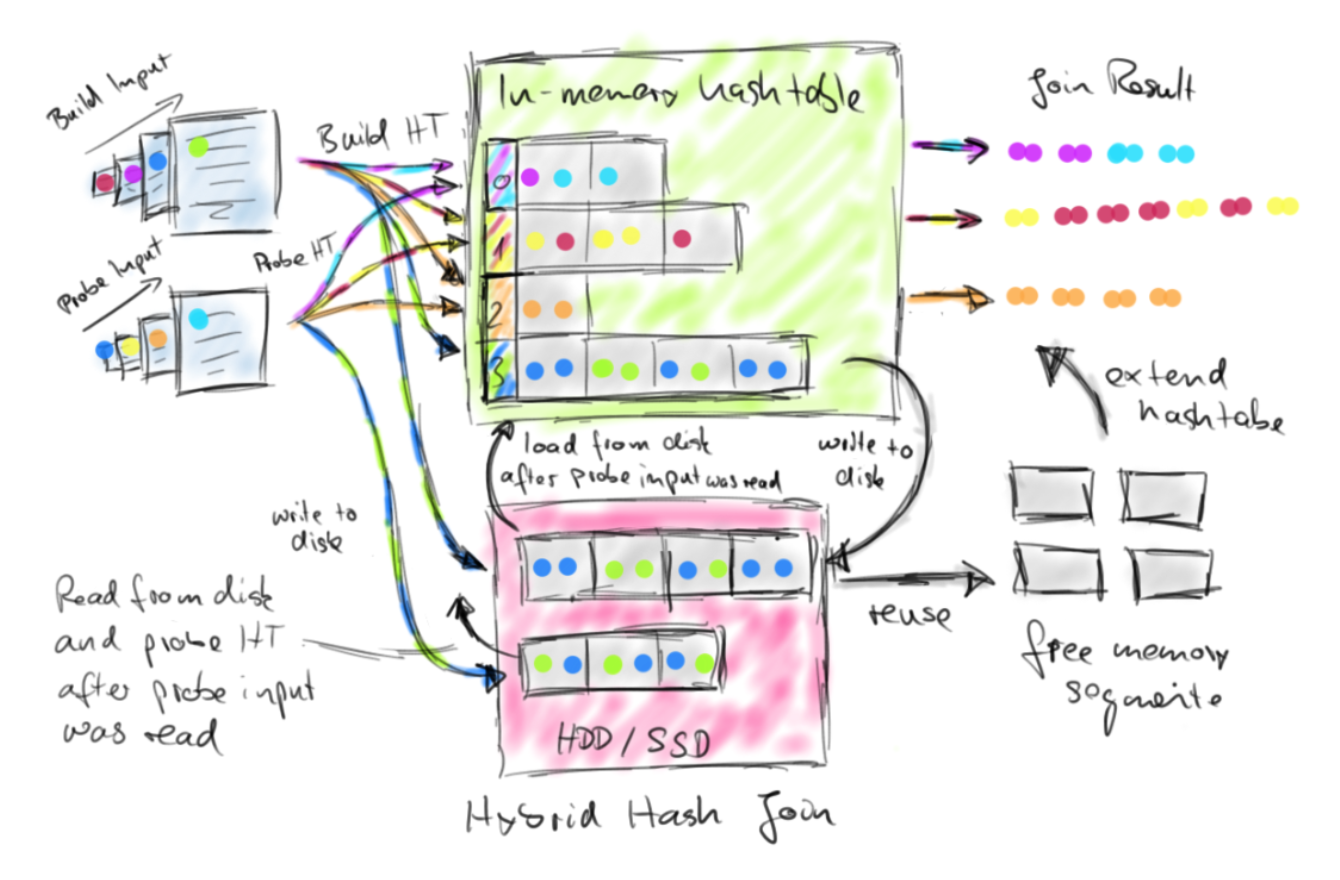
如何选择join策略
传输策略和本地策略互不依赖,可以独立选择。因此,Flink可以通过将三种传输策略(RR,BF与R端广播,BF与S端广播)中的任何一个与三个本地策略(SM,HH与R作为build端,HH与S作为build端)中的任何一个相结合。这些策略组合中的每一种都会根据数据大小和可用内存而执行有差异。对于较小的数据集R和较大的数据集S,广播R并将其用作Hybrid-Hash-Join的构建侧输入通常性能不错,因为没有网络传输,也不使用较大的数据集S实现(假设哈希表小于内存)。如果两个数据集都很大,或者在许多并行实例上执行了联接,则对两个输入进行重新分区是一个明智的选择。
Flink具有基于成本的优化器,该优化器会自动为所有算子(包括join)选择执行策略。基于成本的优化这边不细讲,大致是通过计算具有不同策略的执行计划的成本估算,并选择估算成本最低的计划来完成。优化器通过网络传送并写入磁盘的数据量来估算成本。如果无法可靠的估计输入数据的大小,则优化器将使用默认选择。优化器的主要功能是推断现有数据属性。例如,如果已经以一种恰当的方式对一个输入的数据进行了分区,则生成的候选计划将不会对该输入进行重新分区。因此,选择RR传输策略变得更有可能。如果是先前已排序的数据,则会选择sort-merge-join策略。 Flink程序可以通过提供有关用户定义函数的语义信息来帮助优化器推断现有的数据属性。尽管优化器是Flink的杀手级功能,但是,用户比优化器可能更了解如何执行特定的联接。与关系数据库系统类似,Flink提供了优化器提示,以告诉优化器选择哪种连接策略。
Flink的join性能
Flink中的join速度究竟有多快?我们来看一下。我们首先以Flink的Hybrid-Hash-Join实现的单核性能为基准,然后运行Flink程序,该程序执行具有并行度为1的Hybrid-Hash-Join。我们在(2个vCPU,7.5GB内存和两个本地连接的SSD)机器上运行该程序实例。我们为join提供4GB的工作内存。两个输入join时生成1KB记录。我们运行1:N(主键/外键)join,并使用唯一的Integer联接键生成较小的输入,并使用随机选择的Integer联接键生成较大的输入,这些键属于较小输入的键范围。因此,较大侧的每个元组与较小侧的一个元组正好相连。连接的结果将立即被丢弃。我们将构建侧输入的大小从100万个更改为1200万个元素(从1GB更改为12GB)。探针侧输入保持恒定在6400万个元素(64GB)。下表显示了每种设置的三个运行的平均执行时间。
具有1到3GB构建端的连接(蓝色条)是纯内存join。另一个连接将数据部分溢出到磁盘(4到12GB,橙色条)。结果表明,只要哈希表没有超出内存,Flink的Hybrid-Hash-Join的性能就能保持稳定。一旦哈希表超出内存,哈希表的一部分和探测端的相应部分就会溢出到磁盘上。该图表显示,在这种情况下,Hybrid-Hash-Join的性能会适当降低,即,当join开始溢出时,运行时不会急剧增加。结合Flink强大的内存管理功能,这种执行行为可提供平稳的性能,而无需进行细粒度的,与数据相关的内存调整。
因此,即使对于有限的内存资源,Flink的Hybrid-Hash-Join实现在单个线程上的性能也很好,但是当将较大的数据集连接到分布式设置中时,Flink的性能如何?在下一个实验中,我们比较最常见的联接策略组合的性能,即:
- BF + HH
- RR + HH
- RR + SM
不同的输入数据集: - 1GB:1000GB
- 10GB:1000GB
- 100GB:1000GB
- 1000GB:1000GB
广播转发策略最多只能执行10GB。从5GB工作内存中的100GB广播数据构建哈希表将导致每个并行线程大约溢出95GB(构建输入)+ 950GB(探针输入),并且每台计算机上需要8TB以上的本地磁盘存储。
与单核基准测试一样,我们运行1:N联接,即时生成数据,并在联接后立即丢弃结果。我们在10个实例上运行基准测试。每个实例配备8个内核,52GB RAM,其中40GB配置为工作内存(每个核5GB),以及一个本地SSD,用于溢出到磁盘。所有基准测试都是使用相同的配置执行的,即未对相应数据大小进行微调。程序以80的并行度执行。
不出所料,广播转发策略在很小的输入上效果最佳,因为大型探针端没有通过网络运送,而是在本地加入的。但是,当广播侧的大小增加时,就会出现两个问题。传输的数据量增加的同时,每个并行实例也必须处理完整广播的数据集。两种重新分配策略的性能在输入大小增加时表现相似,这表明这些策略主要受到数据传输成本的限制(最大2TB通过网络传输并加入)。尽管sort-merge-join策略在所有显示的情况下均表现出最差的性能,但它在数据已排序的情况下会表现比较好。