对于非常大的数据集,副本往往是不够的,往往需要分区来提高并发和扩展性。
分区和复制
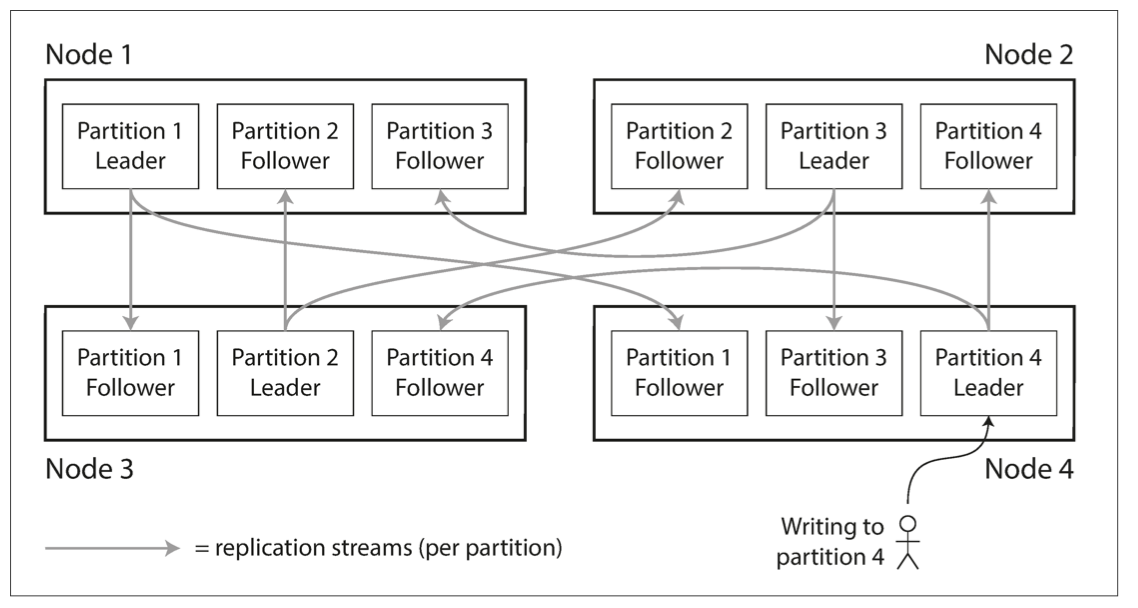
分区也需要通过复制来容错。同时,一个节点可能存在多个分区。下图是一个leader-follower模型的场景。每个节点上可能有leader分区,也可能有follower分区。
键值分区
当数据存储时,如何决定数据存储在哪个分区?
当数据分布不均匀时,就会出现数据倾斜,从而导致热点数据的产生。但是当数据随机分布时,可能并不知道数据在哪个分区,那么在查询时,所有节点都需要查。分区方式一般有根据键的范围分区和根据hash分区。
根据键的范围分区
根据键的范围分区:为每个分区指定一块连续的键范围。这样,就可以快速定位数据在哪个分区。但是为每个分区设置键范围不太容易,因为可能有些键包含数据多,有些键包含数据少。
在每个分区中,可以通过SSTables和LSM Trees来使得key顺序排列。如果key是时间戳,查找某一段时间的数据就会变得非常容易。
但是这可能带来的问题是,写数据时容易往一个分区写。为了防止写入热点,可以在时间戳前面加一个机器编号,使得写入负载均匀分布在每台机器上。但是,这也会损耗查询,因为这时查询时,在每台机器上都得范围查询。
根据hash分区
根据hash分区:根据哈希函数来分区。这种分区方法的好处是使的分区自然随机分布,而且不需要去设定每个分区的边界。但是带来的问题就是无法高效执行范围查询。任何范围查询都必须到所有分区中去查询。

cassandra综合了以上两种分区。cassandra表可以使用多个列组成的复合主键来声明。键中第一列是hash的,其他列被用作SSTables中排序数据的连接索引。这样在第一列固定的情况下,就可以进行范围查询。
负载倾斜和消除热点
hash分区可以帮助减少热点,但是当对某一些key进行大量查询时,hash分区就无能为力了。举个例子,当微博出现某个明星的热点访问时,就会引发对某个key的写。针对这种情况,可以在key前面加随机数,这样可以一定程度上消除热点。但是同样的,读数据时就必须付出一定代价。
分区和次级索引
次级索引一般用于特定的查询。比如,用户123的所有的操作,包含hogwash的所有文章,所有红色的汽车,等等。
次级索引在关系型数据库、文档型数据库(MongoDB)、搜索引擎(ES)中很常见,但是在很多键值存储中(HBase)就很少用到,因为会增加复杂度。
次级索引的问题是它无法整齐的映射到分区。有两种次级索引的方法:基于文档的(document-based)分区和基于关键词(term-based)的分区。
基于文档的次级索引
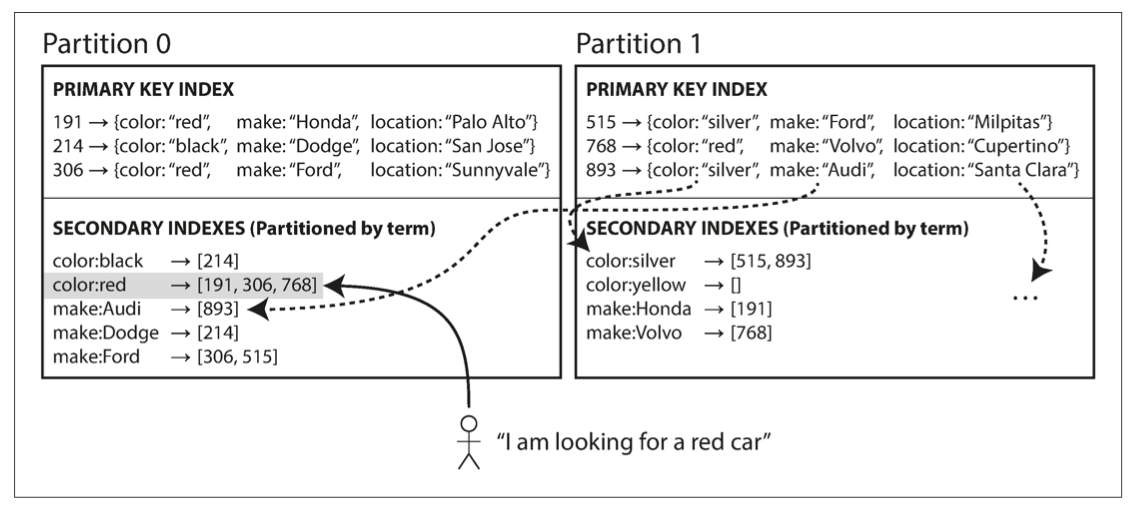
基于文档的次级索引在各自的分区中各自维护。如下图所示,color和make是两个次级索引,它们只存了本地分区的主键。因此基于文档的次级索引也叫local index。基于文档的次级索引优点是,增删改数据时,只需要对本地的索引进行修改即可。缺点是在查询时,每个分区都需要查。这种查询分区的方式也叫做分散/聚集。
根据关键词的次级索引
根据关键词的次级索引是覆盖所有数据的全局索引,而不是每个分区单独维护各自的索引。同时,为了防止单点瓶颈,它也是分区的,分区方式可以与主键的分区方式不同。

关键词分区的优点是不需要分散/聚集,这样读就更快。缺点是写入慢且复杂,可能会影响多个分区。同时,如果需要索引是最新的,就必须引入跨分区的分布式事务。但是一般情况下,为了保证性能,全局次级索引都是异步的。
分区再平衡
再平衡指的是负载从一个节点迁移到另一节点的过程。再平衡的过程需要满足以下三点:
- 负载均衡
- 再平衡过程时读写可用
- 节点之间只移动必要的数据
平衡策略
分区分配策略大致有以下几种:
hash mode N
当通过hash分区时,数据hash后除以N(节点数)的余数就是对应存入的节点分区。带来的问题是当N发生变化时,分区数也会发生变化,需要的移动的数据会比较多。
固定数量的分区
固定数量的分区是指一开始设置非常多的分区,远大于节点数。这样,每个节点上分布着固定数量的分区。当节点数增加时,从每个已有节点上分一部分分区到新节点上。这样的好处是分区数不变,键所指的分区也不会变,唯一改变的是分区所在的节点。ES、CouchBase使用的就是这种分区方式。它的缺点是需要一定的经验来设置多少分区,以应对未来的数据增长。分区太大再平衡和节点故障恢复会比较慢,分区太小产生太多开销。
动态分区
按键的范围进行范围分区时,会动态创建分区(HBase)。当分区增大到超过默认值时,就会分成两个分区。相反,如果两个相邻的分区数据被删的很少时,则会自动合并成一个分区。同时需要对分区进行预分区,否则刚开始时,负载会集中在一个分区中。
按节点比例分区
按节点比例分区是指每个节点有固定数量的分区。当节点增加时,分区数也按比例增加,新增加的分区从现有分区中随机分裂出来,以保证负载均衡。
手动or自动平衡
在选择再平衡方式时,有手动和自动两种方式。自动的好处就是不需要人干预,但是过程不可预测。手动虽然麻烦,但是可以防止意外发生。
请求路由
当客户端发起请求时,如何知道去连接哪个节点?这个问题也叫做服务发现(service discovery)。一般有以下几种方案:
- 允许客户端连接任何节点(可以通过round-robin来负载均衡)。如果这个节点可以处理这个请求,则直接处理,否则转发给其他节点。
- 首先把请求发送到路由层,它会决定把请求发送到哪个节点。这个路由层自己不做请求处理,只做分区的负载均衡。
- 客户端知道节点的分区,可以直接连接到正确的节点。
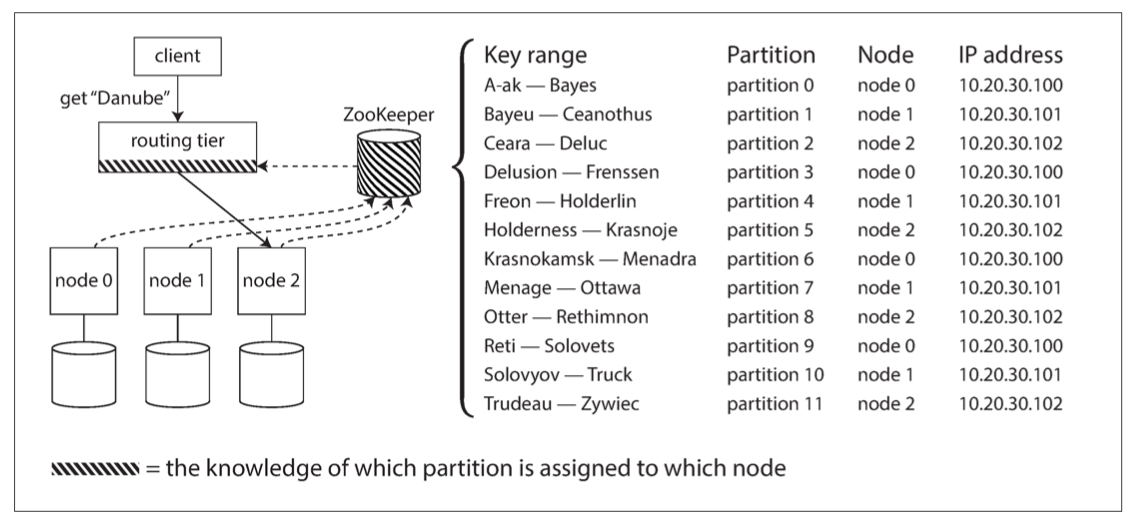
上面的问题核心是:谁来负责路由,如下图所示。

这边有一个一致性问题,也就是做出的决定如何被其他参与者同意。许多分布式系统依靠外部服务,比如zookeeper。每个节点注册到zookeeper中,zookeeper维护节点与分区的关系。比如,路由层可以订阅这个消息。只要节点和分区发送变化,zookeeper就会通知路由层。
并行查询
通常用于分析的大规模并行处理(MPP, Massively parallel processing) 关系型数据库产品在其支持的查询类型方面要复杂得多。一个典型的数据仓库查询包含多个连接,过滤,分组和聚合操作。 MPP查询优化器将这个复杂的查询分解成许多执行阶段和分区,其中许多可以在数据库集群的不同节点上并行执行。涉及扫描大规模数据集的查询特别受益于这种并行执行。