复制可用于以下几个目的:
- 高可用
- 断开连接的操作
- 延迟
- 扩展
Leaders & Followers
复制的定义:每个节点存储一份数据拷贝。
多个副本的情况下:如何保持数据的一致性?
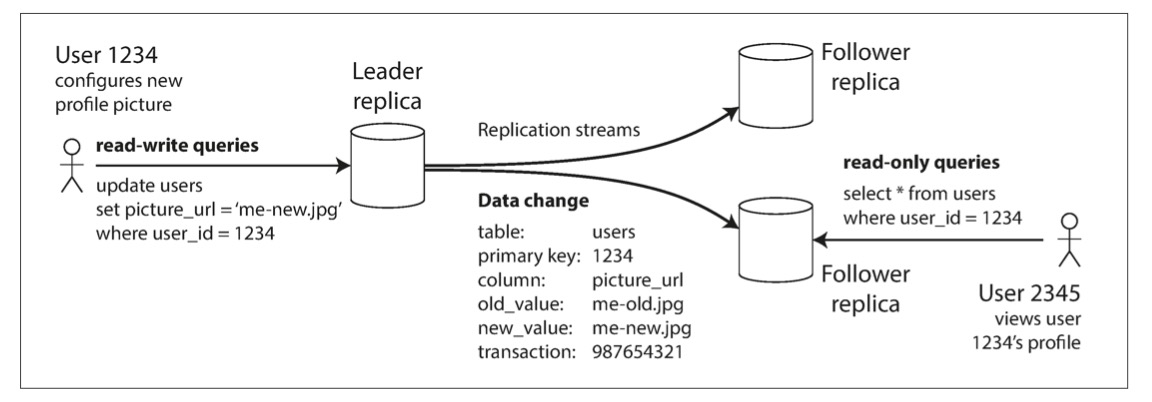
最常用的方法是基于leader的复制。leader负责读写数据,follower只负责读数据。同时leader会把写的数据同步到follower中去。关系型数据库,比如MySQL、Oracle,非关系型数据库,比如MongoDB,消息队列,比如Kafka都是用的这种模式。
异步 vs 同步复制
下图展示的是常用的一种复制场景。一个leader,两个follower。在写数据时,只要有一个follower完成复制,则响应完成。这样可以确保有一个follower的数据是跟leader一致。缺点是如果全部follower无响应,则会block写操作。这种复制方式也叫semi-synchronus。

增加新的Followers
在增加新的followers,如何确保新的followers的数据与leader保持一致?
- 取leader在某一时刻的快照;
- 复制快照到新的followers;
- followers连接leader获取快照之后的数据。这时需要知道快照在log中的准确位置;
- 当followers同步完之后的数据,则整个过程结束。
节点失败
节点失败分为:leader失败和follower失败
follower失败
因为follower知道失败前的log位置,当恢复时可以根据当前位置从leader中获取最新数据。
leader失败
leader失败并恢复的过程也叫做failover。一般分为以下几步:
- 判断当前leader失败。一般根据超时机制来判断。
- 选举新的leader。一般选举数据最新的follower成为leader。这其中存在数据一致性问题。
- 系统使用新的leader。确保老的leader恢复时能够意识到它不再是leader。
failover非常容易出错:
- 如果使用异步复制数据,新的leader可能会存在数据丢失。而且当老的leader恢复时,可能会与新的leader存在数据冲突。最简单的方式是老的leader中没有复制的数据直接丢弃,但这会与客户端的持久性相违背。
- 当与外部存储系统相联系时,把写丢弃时很危险的。比如以前的Github事故,MySQL的follower数据没有及时更新时leader失败了。同时数据库使用自增计数器来生成主键。但是新的leader因为数据延迟会产生与老的leader相同的主键。这些主键同时会在redis中使用,这就引发了redis的数据错误。
- 在某些场景下,两个节点会相信自己都是leader,这就会产生脑裂。
- 如何正确的配置leader失败的超时时间。如果太长的话,需要恢复的时间就会比较长;太短的话,可能会触发不必要的failover。因为可能是短暂网络堵塞引发的,而并不是真正的失败。
这些问题 - 节点失败、不可靠网络、复制一致性,持久性、可靠性和延迟的trade-off - 是分布式系统的基本问题。
复制日志的实现
基于leader的复制底层是如何工作的?
基于statment的复制
leader把收到的请求(statement)发送给follower,follower在收到statement时执行。可能存在的问题:
- 任何statement可能时不确定性的函数,比如now()函数。
- 如果statement使用自增列或者依靠存在的数据,则执行的顺序必须在每个副本节点上保持一致。
- 有副作用的statement,(例如,触发器,存储过程,用户定义的函数)可能会在每个复制节点上产生不同的副作用,除非副作用是绝对确定的。
在MySQL5.1之前,使用基于Statement的复制。后面的版本则在存在不确定statement的情况下,使用基于row的复制。
基于WAL的日志复制
leader收到写请求时,会把请求增加到到只增日志中去,同时把日志发送给follower。只增日志有以下两种实现方式:
- 基于SSTables 和 LSM-Trees
- 基于B-Trees
这种方式的缺点是复制与存储引擎强耦合。不太可能在leader和follower上运行不同版本的数据库软件。
逻辑(基于row)日志复制
逻辑日志的产生是为了解决与存储引擎强耦合的问题。
在关系型数据库中,逻辑日志为:
- 对于插入操作,日志包含所有列的新值。
- 对于删除操作,日志包含足够的信息来唯一确定被删除的row
- 对于更新操作,日志包含足后的信息来唯一确定被更新的row和新值。
因为逻辑日志与存储引擎解耦,它更容易向后兼容,允许使用不同版本的数据库软件。
基于触发的复制
触发器可以允许使用自定义代码来实现数据复制。
复制延迟问题
绝大多数情况使用异步follower复制,这虽然缓解了延迟的问题,但是只能保证最终一致性。
读自己的写
读自己的写的意思是写完之后,自己立马可以看到。但是当使用异步复制时,就会出现问题。这时,需要读写一致性(read-after-write consistency)。有那么几种实现方法:
- 当读取用户可以修改的数据时,从leader中读取。其他情况从follower中读取。适用于可修改数据较少的情况
- 对于可修改数据较多时,可以跟踪上次更新的时间,在上次更新后的一分钟内,从leader读。还可以监控follower的复制延迟,阻止从延迟超过1分钟以上的follower中读取数据。
- 客户端记住最近一次写的时间戳,在follower中进行读取数据时,需要对比follower中记录的时间戳。尽可能从比较新的时间戳的follower中读取数据。时间戳可以是逻辑时间戳,比如日志序列号,也可以是系统实际时间,但是这时候需要考虑时钟同步。
- 在多个数据中心复制时,需要当前leader将请求路由到其他数据中心的leader中。
另一个问题是跨设备读写一致性。这时需要考虑以下问题:
- 记住用户上次更新时间戳的方法变的困难。元数据需要被中心化。
- 如果复制在不同数据中心,需要把来自同一用户的请求路由到同一个数据中心。
单调读
用户在多次读取数据时,可能先从比较新的follower中读取数据,接着从比较旧的follower中读取数据,这样就会出现数据倒流的情况。

单调读就是确保上述情况不发生。它是在强一致性和最终一致性中间。一种实现方法是同一个用户总是从同一个副本中读取数据,比如hash用户id。
一致前缀读
当两个人在聊天时,可能出现答在问之前。

一致前缀读可以解决上述情况。如果一系列写入按某个顺序发生,任何人读取这些写入时,也是按照这个顺序。解决方案是比如加入因果关系依赖算法。