引言
随着有状态流处理逐渐成为复杂时间驱动应用和实时分析系统的应用的越来越多,Flink逐渐成为业务逻辑处理和数据资产的基石。
为了使Flink开发者更好的体验状态处理,Flink社区在提供安全可靠的状态管理模式上作了很多工作。特别是,Flink开发者需要有足够多的手段来获取和修改状态。这些功能体现在多个Flink发布版本中:
- Flink可演进的状态schema
- 与状态后端交互的灵活性
- 状态处理API:一个读写,修改状态的工具
这篇文章讨论社区关于Flink状态管理的相关工作,Flink如何使用不同的API和功能来改善现有的状态管理方式或者增加新的状态管理方式。
流处理:什么是状态
首先解释流处理中状态的含义。有状态的流处理,状态主要由实时的(无界的)或者离线的(有界的)流经应用的数据信息构成。绝大多数不太重要的应用都是内置状态的:即使是简单的count操作,当数到10时,也需要记住已经数到9。
为了更好的了解Flink如何管理状态,可以把Flink想象成一个三层的状态抽象,如下图所示。
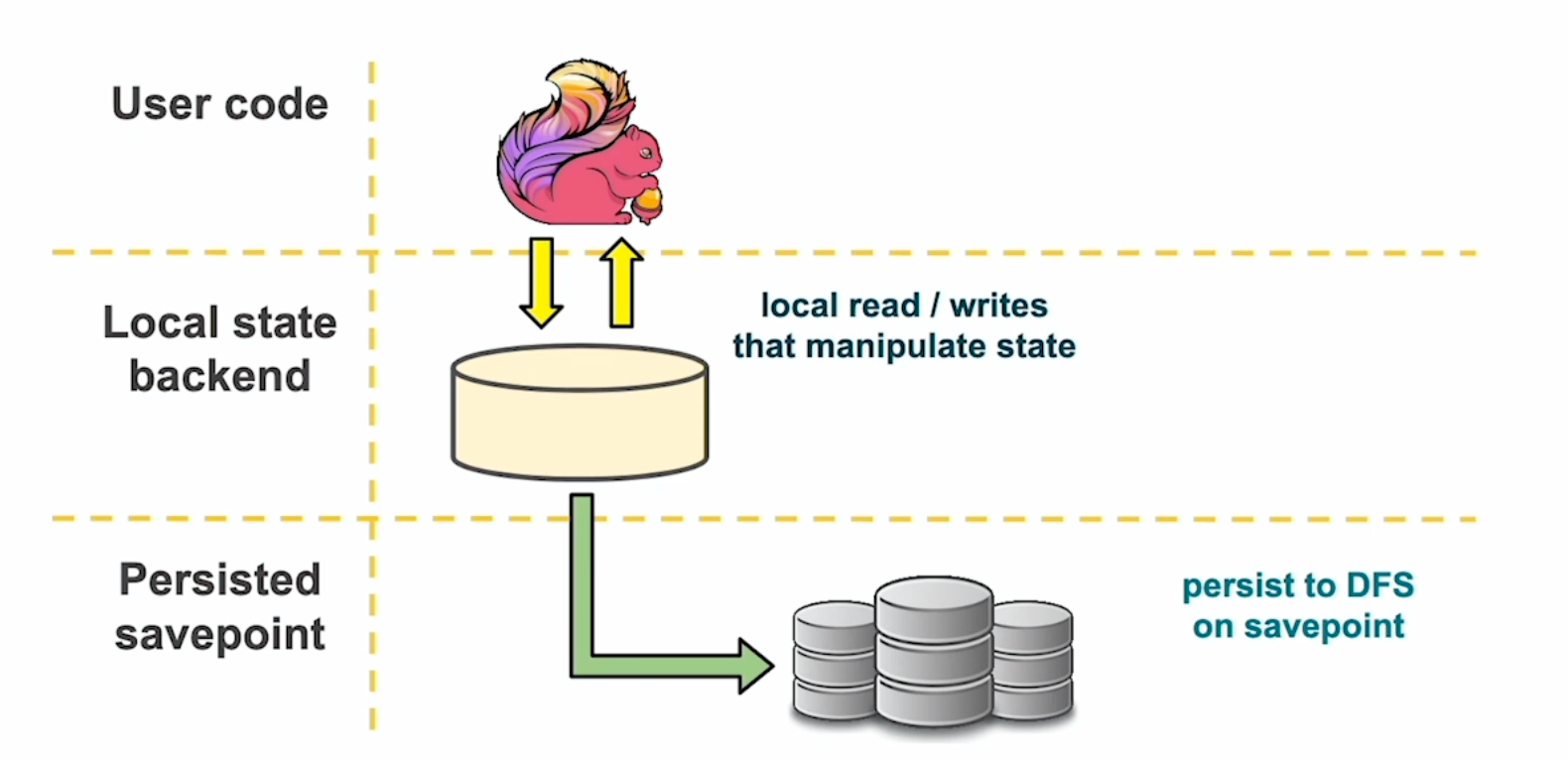
在最上层,是Flink的用户代码,举个例子,KeyedProcessFunction包含了一些值的状态。这是一个简单的变量,它的值状态含义使它在运行时可以自动容错,扩展和查询。根据配置的状态后端,这些变量留在堆上或者磁盘上(RocksDB),同时提供数据位置。最后,在升级时,比如引入新的功能或者bug修复,为了能够保持状态的有效,就引入了savepoints。
savepoint是一个应用在某个逻辑时刻的分布式的全局状态快照,并存储在外部的分布式文件系统或者HDFS、S3中。升级应用或者实现代码的变动 - 比如增加新的算子或者修改一个字段 - Flink任务通过状态后端的savepoint来加载状态就可以无缝衔接。

FLINK的Schema演进
想象这样一个Flink应用,它实现了KeyedProcessFunction函数并包含一些ValueState。因为有状态描述符,当注册一个类型时,Flink用户可以通过设置TypeInformation来告知Flink如何序列化字节。Flink的类型内在支持所有的基本类型比如longs、string、doubles、arrays和基本的集合类型比如lists和maps。此外,Flink还支持绝大多数重要的组合类型,比如Tuples、POJOS、Scala Case CLasses和Apache Avro。最后,如果一个应用的类型与上面的不匹配,开发者可以定制自己的序列器,或者使用Kryo。
通过FLink内部的序列化进行状态注册
1 | public class MyFunction extends KeyedProcessFunction<Key, Input, Output> { |
一般而言,应用的schema演进主要是因为业务逻辑的改变(增加或者减少字段或者修改数据类型)。在所有的例子中,schema是由它的序列化器决定,这可以想成数据库中的改变表声明。当一个状态变量第一次通过CREATE_TABLE命令来生成时,在执行上有很多选择。但是,当数据已经在表中时就会有很多限制,就必须使用ALTER_TABLE命令来升级或者修改表。Flink的Schema迁移遵循类似的原则,因为在savepoint上运行ALTER_TABLE也是非常有必要的。
Flink1.8支持了Apache Avro(特别是1.7.7 specification)。通过Avro,演进的状态schema可以增加和移除类型,一般的和特殊的Avro数据类型交换。
在Flink1.9中,社区增加了POJOS的schema演进支持,包括从POJO类型移除已有字段和增加字段的能力。POJO的schema演进灵活性一般 - 与Avro比较 - 因为不太可能改变已经申明的字段类型或者POJO的类名,包括namespace。
随着社区关于schema演进的工作的推进,Flink开发者现在能够使用Avro和POJO格式来使得Flink状态后端向后兼容。未来的工作将是支持Scala Case Ckasses、Tuples和其他格式。
内部实现
Flink一直把状态当作API稳定性的核心,这样开发者总是能够从一个savepoint中恢复应用。由于schema演进,每次迁移需要向后兼容,并同时与不同的状态后端兼容。但是在Flink中,状态后端通过接口形式来处理存取字节。在实际情况中,这些状态后端区别很大,这就额外增加了schema演进的复杂度。
举个例子,堆状态后端支持懒序列化和快速的反序列化,使得总是在处理Java对象,序列化是在后台线程中执行。当应用恢复时,Flink将快速的反序列化数据然后执行用户代码。如果开发者插入了一个新的序列化器,反序列化是在Flink收到这个信息之前就发生的。
RocksDB状态后端是以完全相反的方式工作:它支持快速序列化 - 因为数据是存在硬盘上,并且RocksDB只消费字节数组。RocksDB提供懒反序列化是简单的通过下载文件到本地磁盘,使得Flink并不知道字节是什么直到序列化器被注册。
另一个挑战来源于不同用户代码版本在classpath上包含不同类,使得序列化器在运行时可能无法写savepoint。
为了解决以上挑战,我们引入了TypeSerializerSnapshot。TypeSerializerSnapshot把写序列化器配置存在快照中。当恢复数据时会读取这个配置并且检查与当前版本的兼容性。Flink提供以下操作
- 读配置快照
- 使用新的用户代码
- 检查两者是否兼容
- 使用快照中的字节并向前移动或警告用户
1 | public interface TypeSerializerSnapshot<T> { |
Flink中Avro序列化实现
Apache Avro是一种数据序列化格式,它很好的定义了schema迁移语义并同时支持读写schema。在正常的FLink执行中,读写schema是相同的。但是,当升级应用时,他们可能是不同的,Flink将能够从schema中迁移对象。
1 | public class AvroSerializerSnapshot<T> implements TypeSerializerSnapshot<T> { |
这个是Avro序列化器的模版。它使用提供的schema并且代理给Avro处理所有的序列化和反序列化。让我们看一下TypeSerializerSnapshot在Avro中schema迁移中的实现。
写快照
当序列化一个快照时,快照配置将写两个信息:当前的快照配置版本和序列化器配置
1 |
|
版本是用来标记快照配置版本,当writeSnapshot函数写所有的信息时,我们需要了解当前的格式;运行时schema。
1 |
|
当Flink恢复时,它能够读取写schema曾经序列化的数据。当前运行时schema在classpath中通过java反射机制来发现。
一旦拥有两个schema,就可以比较兼容性。
1 |
|
schema使用Avro的兼容性检查比较,它们要么是兼容的,要么是不兼容的。
1 | final SchemaPairCompatibility compatibility = SchemaCompatibility |
如果迁移时它们是兼容的,Flink将恢复一个新的序列化器,它能够读取旧的schema并且使用新的schema反序列化。
状态处理API:读、写和修改Flink状态
状态处理API允许读写Flink的savepoints。比如:
分析有趣模式的状态
通过检查状态差异来解决任务的问题
为新的应用加载状态
修改savepoint
部署一个Flink任务时修改savepoint的最大并行度
在Flink中引入中断的的schema升级
在Flink savepoint中修正无效的状态
在先前的文章中中,我们讨论了状态处理API的细节,Flink1.9中引入这个功能的动机和如何使用这个API。本质上,状态处理API基于关系模型,把Flink任务状态map到数据库,如下图所示。
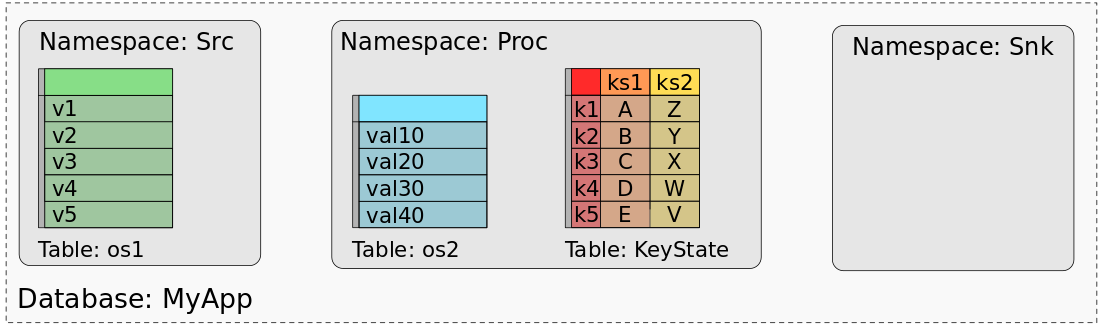

更多与状态交互的方式
在随后的发布版本中,状态处理API将支持从窗口中读写,并且在Flink Table API 和 SQL中集成。
除了扩展状态处理API的使用范围,FLink社区还讨论了其他几种与状态交互的方式。其中一种是对所有的keyed状态后端统一savepoint格式(FLIP-41)。这种方式旨在所有的keyed状态后端的savepoint种引入了一个统一的二进制格式,可以减少状态后端的转换负载。同时,这样可以允许开发者已不同的状态后端重启应用 - 举个例子,heap状态后端和RocksDB状态后端的转换 - 依据应用在不同时刻的扩展性和演进。
社区同时在讨论在Flink的发布版本中加入干运行。这样,Flink允许开发者离线检测不匹配的升级,而不需要启动一个新的Flink应用。举个例子,Flink用户可以在不把状态加载回来或者启动一个Flink应用时,看到任务升级带来的拓扑或者schema的不兼容和从streaming graph中看到注册的状态信息。