Flink的网络栈是flink-runtime中非常核心的模块。TaskManagers的subtask通过它相互相互连接。与用于协调TaskManager和JobManager之间通信的Akka(RPC)不同,它使用的是底层API,Netty。它对Flink任务的吞吐量和延迟性能至关重要。因此,监控它的状态来查看当前的任务瓶颈也是非常必要的。目前有两种监控方式:背压监控和网络监控。
逻辑图
当执行keyby()算子时,Flink会提供subtaks之间相互通信的逻辑图,如下所示:
![][flink-network-stack1.png)
它抽象了三个概念的设置:
- subtask的输出类型
- pipelined(有界 or 无界):尽可能快的one by one的向下游发送有界或无界的数据。
- blocking:只有结果全部生成才往下游发送数据。
- 调度类型
- all at once(迫切的):同时部署任务的所有子任务(流应用)。
- next stage on first output(懒惰的):只有上游有数据产生,就部署下游任务。
- next stage on complete output:上游结果全部生成,才部署下游任务。
- 传输
- 高吞吐:Flink缓存一批数据到网络缓存(network buffer)中,在存满或者超时批次发送(不是一条条的向下游发送)。通过降低每条数据的花销来提高吞吐量。
- 通过缓存超时的低延迟:通过降低缓存的超时时间,可以牺牲吞吐量而换取低延迟。

此外,对于subtask有多个输入的情况,有两种调度方式:所有的输入都完成或者其中一个输入完成一个或全部的结果。对于批作业的调度模型选择,可以设置ExecutionConfig#setExecutionMode()、ExecutionMode 、ExecutionConfig#setDefaultInputDependencyConstraint()。
物理传输
假定2个taskmanger,每个taskmanager提供2个slot,并行度为4。TaskManger1执行subtask A.1,A.2,B.1和B.2,TaskManager2执行subtaskA.3,A.4,B.3和B.4。在taskA和B有shuffle的情况下,比如keyBy(),每个TaskManager就会有2X4的逻辑连接。

不同task之间的远程网络连接都有自己的TCP通道。但是在同一个TaskManager中的的subtask共享同一个TCP通道,这样可以降低资源消耗。
每个task的结果叫做 ResultPartition,根据subtask又可以分成ResultSubpartitions - 对应
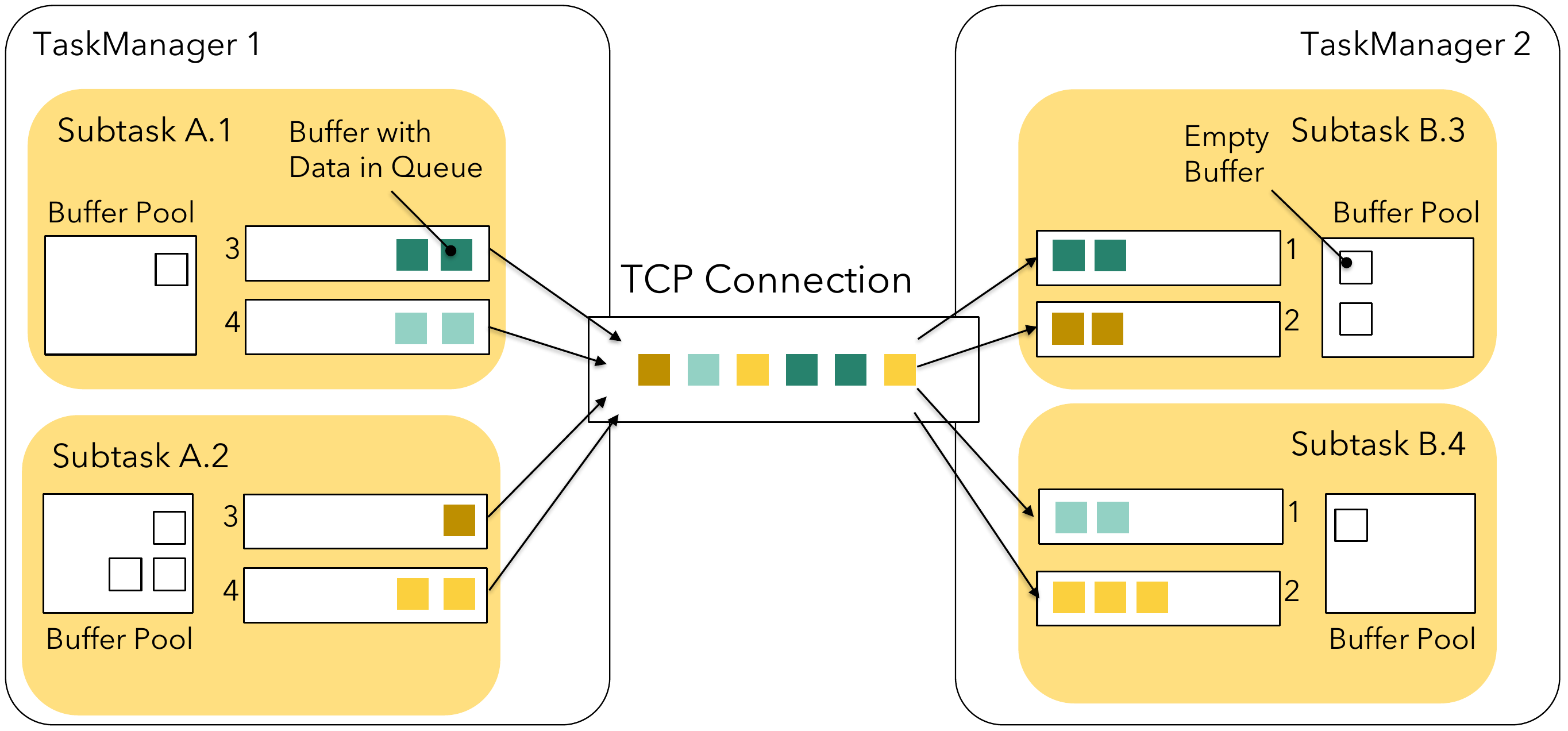
一个逻辑通道。在网络栈中,Flink不再处理单独的数据,而是封装在网络缓存(network buffer)中的一组序列化的数据。每个subtask的缓存从自己的本地缓存池中拿取,计算公式如下:
$$
channels * buffersPerChannel + floatingBuffersPerGate
$$
通常TaskManager的总缓存数不需要设置。如果要设置,可以参考Configuring the 网络缓存(network buffer)s 。
背压问题
在发送端,当一个subtask的发送缓存池被耗尽时-(缓存数据要么被暂存在结果子分区(result subpartiiton)的缓存队列中,要么在Netty网络栈中),那么生产者就会被block住,不能继续发送数据,这就是背压产生的原因。接收端以类似的方式工作:任何进来的Netty缓存需要先通过网络缓存(network buffer)。如果在缓存池中没有可用的网络缓存(network buffer),Flink将会停止读取读取通道数据直到有可用的缓存。这会极大的影响同一个TaskManager之下的多个subtask的共享通道。下图展示了subtask B.4因为没有缓存引起了背压,从而导致B.3在缓存池中还有可用缓存的情况下依然不能接收和处理数据。
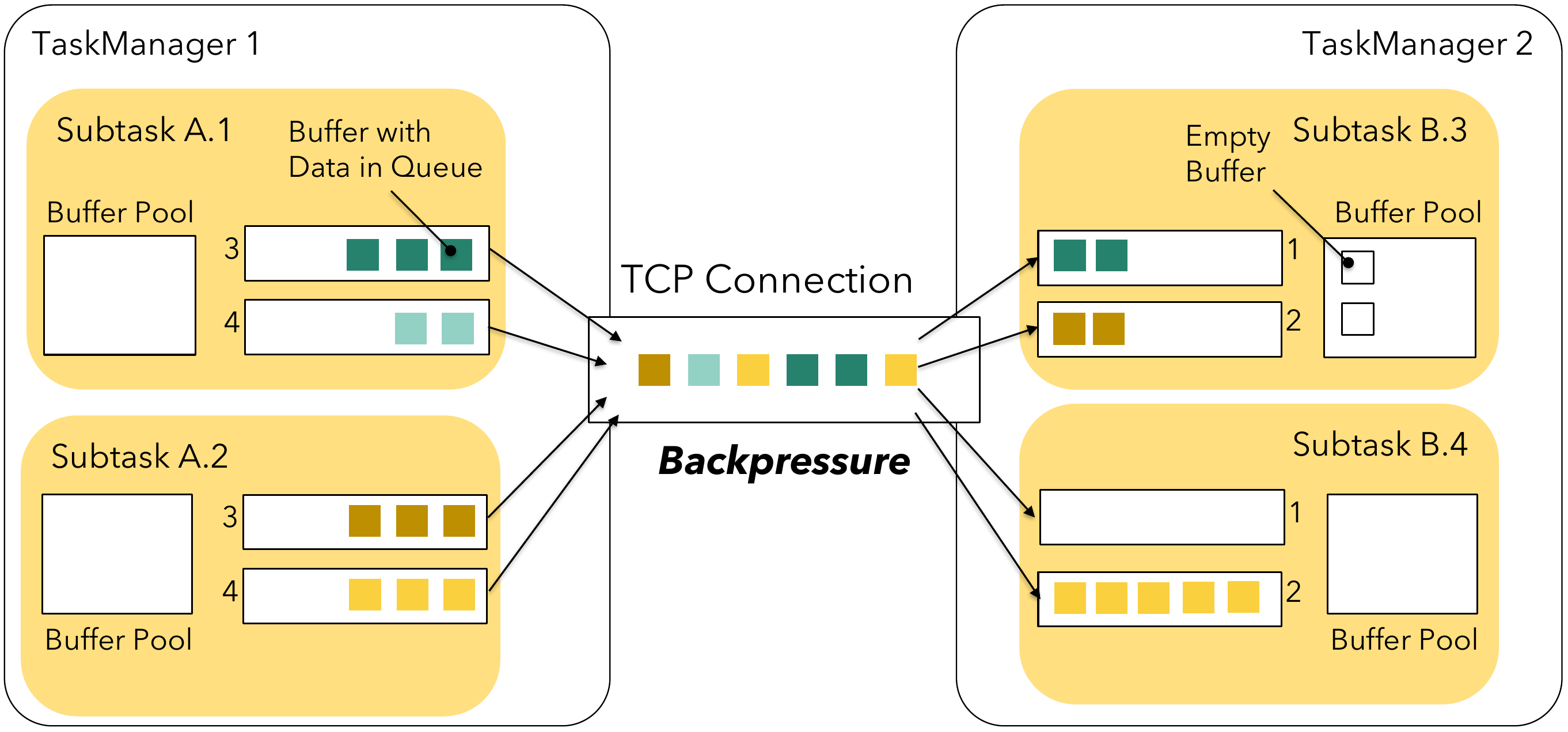
为了阻止这个问题,Flink1.5引入了流控机制。
基于信誉的流控
基于信誉的流控确保了任何subtask都有接收数据的能力。它是对可用网络缓存(network buffer)机制的扩展。subtask不再仅有一个本地缓存池,每个远程的输入通道都有自己的exclusive buffer。同时,在本地缓存池中的缓存叫做floating buffers,因为它们是浮动的,对每一个输入通道都可用。
接收端将会向发送端发送一个可用的缓存数作为credits(1 buffer = 1 credit)。每个结果子分区(result subpartiiton)将会持续追踪它的通道信誉。缓存会向底层网络栈(netty)中前进。在缓存之外,发送端还会发送当前的backlog大小,它表示当前有多少缓存等待在子分区队列中。接收端将获取适当的floating buffer来加快处理backlog。只要有backlog,接收端将会尽可能多的获取floating buffer,但是有时缓存可能被用完。接收端将利用取得的缓存并持续监听可用的缓存。
基于信誉的流控使用 buffers-per-channel来设置有exclusive缓存的数量,使用 floating-buffers-per-gate来设置本地缓存池。这两个参数的默认值是被设置为最大吞吐量的值,也就是没有流控。可以根据网络往返时间和带宽来动态调整这两个值。
如果没有可用的缓存可用,每个缓存池会获取全局可用的缓存。
背压问题
与没有流控的背压机制相反,信誉提供更加直接的控制:如果接收端无法跟上,它的可用信誉将最终减为0,并停止向底层网络栈(netty)发送缓存。这样只会背压这个逻辑通道,而不需要block整个多路复用的TCP通道。因此,其他接收端不会收到影响。
流控的影响
因为流控,多路复用通道不再block其他的逻辑通道,整个资源利用率将会增加。此外,因为能够知道有多少数据被背压,还能够加强 checkpoint alignments:如果没有流控,TCP通道填充和传播网络堆栈的内部缓冲区,需要一定的时间耗费,此时接收方不再读取的消息。在那期间,会出现很多缓存等待的情况。排在这些等待缓存后面的checkpoint barrier需要等到这些缓存被处理掉,它才能继续前进,这样就增加了checkpoint对齐的时间。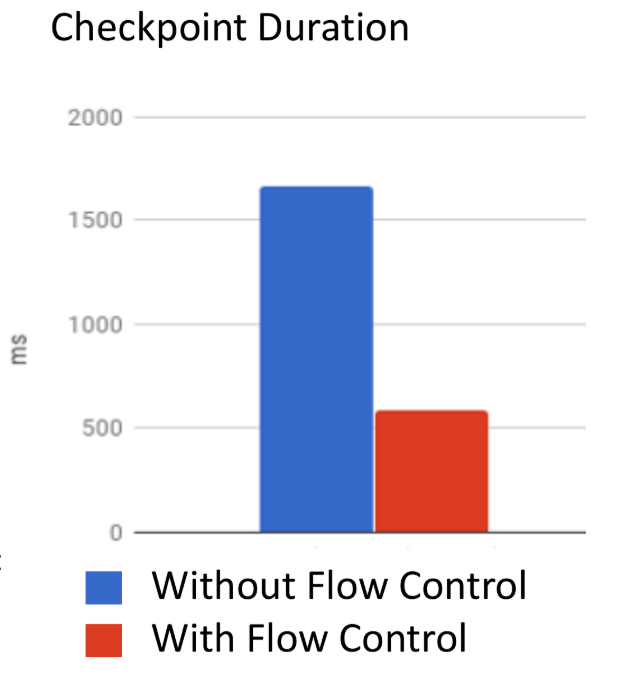
但是,接收端额外的消息声明会引起额外的一些损耗,特别是在SSL加密的通道设置中。另外因为exclusive buffers不是共享的,单个输入通道不能使用缓存池中的所有缓存。同样,发送端无法发送尽可能多的数据(不能超过返回的信誉值),这样可能需要耗费更多的时间来发送数据。虽然这会影响任务的性能,但是通常使用流控会有更好的优势。虽然增加的exclusive buffers会耗费更多的内存,但是整体内存使用会更低,因为底层网络栈(netty)不再需要缓存更多的数据。
使用流控的另外一个好处是:因为在接收端和发送端缓存更少的数据,从而会更早的发生背压。如果想要缓存更多数据的话,可以通过设置 floating-buffers-per-gate来增加floating buffer的数量。
可以通过taskmanager.network.credit-model: false来关闭流控。不过这个选项将在以后的版本中移除。
Network Buffer数据的读写
下图展示了简化的网络栈视图与它的组件。
RecordWriter把java对象序列化,并放入网络缓存(network buffer)中。RecordWriter首先使用SpanningRecordSerializer序列化数据到一个可扩展的堆字节数组中。然后,它尝试把这些字节数组写入目标网络通道中的网络缓存(network buffer)中。
在接收端,底层网络栈把收到的缓存写入合适的输入通道中。task线程最终会读取这些缓存队列并通过RecordReader的SpillingAdaptiveSpanningRecordDeserializer尝试把这些反序列化成java对象。与序列化类似,反序列化器也必须处理特殊的情况,比如因为数据太大(默认32kb,通过taskmanager.memory.segment-size设置)分散在多个网络缓存(network buffer)中,或者因为网络缓存(network buffer)没有过多剩余的buffer导致数据被打散。
往Netty中刷新缓存
在上图中,基于信誉的流控机制实际是在”Netty Server”组件中,RecordWriter写的缓存会被添加到结果子分区(result subpartiiton)。但是Netty什么时候开始获取缓存呢?显然,它不能随意的去刷新字节,因为这不仅将增加跨线程通信和同步的花费,还会使得整个缓存过期。
在Flink中,有三种情况Netty server可以获取可用的缓存:
- 当缓存被数据写满
- 缓存超时触发
- 特殊事件,比如checkpoint barrier
网络监控
网络监控中主要的就是 monitoring backpressure。当系统收到的吞吐量高于能处理的吞吐量时,就会导致背压,这主要有两种原因:
接收端处理慢。有可能是因为接收端自己也是背压,作为发送端无法持续发送数据。或者因为垃圾回收,缺乏系统资源比如I/O等。
网络通道慢。在这种情况下,接收端没有直接涉及。背压产生由于发送端过度消耗机器的共享网络带宽。因为其他组件也需要耗费网络资源,比如sources和sinks,分布式文件系统(checkpointing, 基于网络的存储),logging和metrics。
如果背压发生,它会向上游传递最终会到sources,并使得sources减速。这对于资源不足的情况而言不是坏事。但是,如果想改进你的任务,从而使得在不消耗更多资源的情况下获得更高的负载。这样,就必须找出瓶颈在哪个地方和如何引起的。Flink提供两种机制来发现瓶颈:
直接通过Flink的Web UI来监控背压
通过对网络的监控
Flink的web UI可以最直接了解背压情况,但是它会有一些缺陷。网络监控对于持续监控的支持是非常好的,并且可以解释背压产生的原因。
背压监控器
backpressure monitor仅在Flink的Web UI中显示。它是被请求触发的。它通过Thread.getStackTrace()方法来采样task线程,并计算task被缓存请求block的采样结果。这些task要么不能以它们产生缓存的速度发送网络缓存(network buffer),要么下游tasks基于信誉减速上游的发送速率。背压监控器将显示所有请求的block率。一些背压被认为是正常的/暂时的,总共有以下三种状态:
- OK。ratio <= 0.10
- LOW 0.10 < ratio <= 0.5
- HIGH 0.5 < ratio <= 1
虽然可以调整刷新间隔,采样数量和采样间的延迟参数,但是在正常情况下,使用默认值就可以。
背压监控器虽然可以找出背压的出处,但是不能找出原因。另外,对于大任务或者高并行的任务,背压监控器采集数据可能会比较慢。同时它也会影响任务的性能。
网络监控
Network和task I/O监控是一种更加轻量级的监控,并且每个任务会持续输出这些指标。主要的指标如下:
Flink1.9以上:outPoolUsage
,inPoolUsage,floatingBuffersUsage,exclusiveBuffersUsage。inPoolUsage是floatingBUffersUsage和exclusiveBuffersUsagee的总和。
numRecordsOut, numRecordsIn
每个指标有两个维度:算子维度和subtask维度。对于网络监控,使用subtask维度来展示它收到和发送的数据。同时 ,还需要关注一下对等的…PerSecond指标。
numBytesOut, numBytesInLocal, numBytesInRemote
subtask发出或者从本地或者远程读到的字节总和。同样有…PerSecond指标。
numBuffersOut, numBUffersInLocal, numBuffersInRemote
与numBytes…类似,但是计算的是网络缓存数。
背压
背压可以通过两种不同的指标来展示:本地缓存池使用情况和输入/输出队列长度。它们的粒度不同。输入/输出队列长度指标因为内在的问题,这边暂不讨论。对于缓存池的情况:
如果subtask的outPoolUsage是100%,它就被背压了。它是否已经block或者一直在等待数据进入网络缓存(network buffer)取决于这个缓存是有多满。
如果subtask的inPoolUsage是100%,意味着所有的floating buffer已经被分配到通道中去,而且产生的反压会向上游传递。这些floating buffers有以下几种情况:它们被exclusive buffer使用(远程输入通道总是尝试保持 exclusive buffer信誉)或者被backlog使用(包含数据和被装在输入通道中或者包含数据和正在被接收端的subtaask读取)。
Flink1.9以上:如果inPoolUsage总是在100%左右,就表明反压正在向上游传递。

从上面还可以得出:如果接收端所有的subtasks的inPoolUsage是低的,而且它上游的outPoolUsage是高的,那么背压可能是由网络瓶颈引起的。因为网络是共享资源,所以可能是自身占用的网络资源太多,或者是其他操作占用太多的网络资源。
背压也有可能由一个task实例引发。这个task的所有分区可能正在执行耗时的操作或者是数据倾斜。
如果floatingBufferUsage不是100%,不太可能出现背压。如果floatingBufferUsage是100%,并且上游task也是背压的,往往可能是单个或多个输入通道在背压。可以通过exclusiveBuffersUsage来区分不同的情况:
- 假设floatingBufferUsage是100%,exclusiveBuffersUsage越高,输入通道越有可能出现背压。在exclusiveBuffersUsage接近100%的极端情况下,可能所有的输入通道都是背压的。

资源使用/吞吐量
除了上面的指标使用,还可以与其他指标结合来查看网络的情况:
- 低吞吐,经常性的outPoolUsage在100%附近,但是接收端inPoolUsage非常低:表明信誉通知的往返时间比较长。可以考虑增大buffers-per-channel 参数或者尝试关闭流控。
- 与numRecordsOut和numBytesOut结合,可以算出序列化的数据的平均大小,来估算峰值场景。
- 如果想找出缓存填充率的原因和输出刷新的影响,可以结合numBytesInRemote和numBUffersInRemote。当调节吞吐量指标时,低的缓存填充率表明网络效率的降低。在这种场景下,考虑增加buffer超时时间。在Flink1.8或者1.9中,numBuffersOut仅在缓存满时或者遇到checkpoint barrier时才会增加,这会导致一定的延迟。本地通道的缓存填充率是不必要的,因为远程通道的优化技术对本地通道没什么用。
- 通常情况下,numBytesInLocal和numBytesInRemote分开计算没什么必要。
背压如何解决
如果背压产生了,下一步就是分析它是如何产生的。首先需要检查基础的指标。
系统资源
首先,需要检查机器的资源利用率,比如CPU,网络或者磁盘I/O。如果资源已充分利用,可以尝试:
- 优化代码
- 调优Flink的资源
- 扩大并行度或者增加机器的数量
垃圾回收
有时性能问题是由GC引起的。可以通过-XX:+PrintGCDetails来打印GC日志,或者使用GC分析器。
CPU/线程瓶颈
有时CPU瓶颈不太容易察觉。比如有些线程引起了瓶颈,但是整个机器的CPU利用率还是比较低的。可以考虑使用代码分析器来定位热线程。
线程竞争
与CPU/线程瓶颈类似,subtask可能由于线程竞争导致瓶颈。CPU分析器可以帮助定位同步/锁竞争。
负载不均衡
如果由于数据倾斜引起,可以尝试改变数据分区(分开热点key或者是用local/pre-aggregation)。
延迟追踪
在低吞吐情况下,延迟通常被输出刷新器影响,可以通过调节缓存超时时间或者修改代码来改善。当处理一条数据的时间超过了期望值,或者多个计时器在同一时间触发,就会block接收端处理数据的能力。
Flink提供了 tracking the latency来追踪通过系统的数据。但是开关默认是关闭的。可以通过 metrics.latency.interval或者ExecutionConfig#setLatencyTrackingInterval()来设置。开启后,Flink将会根据metrics.latency.granularity来收集不同粒度的延迟矩形图。
- single:每个算子的subtask一个矩形图
- operator(默认):每个source task和算子 subtask的并集一个矩形图
- subtask:每个source subtask和算子subtask的并集一个矩形图
这些指标通过特殊的”延迟标记”收集:每个source subtask将周期性发出一条延迟标记,它随着正常数据流动,但是不参与计算和缓存队列。延迟标记因此仅仅度量用户代码之间的等待时间,而无法做到端到端延迟追踪。而且,用户代码会间接的影响等待时间。
因为延迟标记像正常数据一样坐落在网络缓存中,它们可能会等待缓存被填满或者缓存超时。当一个通道是高负载的时候,不会增加网络缓存数据的延迟。但是,一旦通道是低负载的,数据和延迟标记将会有一个平均的buffer_timeout/2的延迟。这个延迟会被增加到每个网络连接当中去,因此在分析subtask的延迟指标时,需要把这个考虑进去。
通过查看每个subtask暴露的延迟追踪指标,应该可以定位到哪个subtask增加了整个链路的延迟。
开启延迟监控会显著影响集群性能,特别是subtask尺度。推荐在debug时使用。
总结
本文介绍了批处理和流处理不同的网络连接和调度类型。介绍了基于信誉的流控机制和内部网络栈工作的原理,以及它们的背压情况。通过背压监控器可以找到背压的源头,通过网络监控,结合其他系统指标,比如CPU、GC、线程等,可以找到背压的原因。
参考
A Deep-Dive into Flink’s Network Stack
Flink Network Stack Vol. 2: Monitoring, Metrics, and that Backpressure Thing